Getting started
Fitting a data to a user defined model
refnx can examine most curve fitting problems. Here we demonstrate a fit to a simple user defined model. This line example is taken from the emcee documentation and the reader is referred to that link for more detailed explanation. The errorbars are underestimated, and the modelling will account for that.
To use refnx we need first need to create a dataset. We create a synthetic dataset
%matplotlib inline
import numpy as np
rng = np.random.default_rng(1220289787)
# Choose the "true" parameters.
m_true = -0.9594
b_true = 4.294
f_true = 0.534
N = 50
x = np.sort(10 * rng.uniform(size=N))
yerr = 0.1 + 0.5 * rng.uniform(size=N)
y = m_true * x + b_true
y += np.abs(f_true * y) * rng.normal(size=N)
y += yerr * rng.normal(size=N)
We create a Data1D object from this synthetic data:
from refnx.dataset import Data1D
data = Data1D(data=(x, y, yerr))
Then we need to set up a generative model. Firstly we write a fit-function that returns our straight line model. The Parameter objects describe the parameters we’re going to use in the fit. We give the parameters values, names, and specify their limits. The parameters are combined into a Parameters set, p, using the or operator.
Then we create a Model object from our parameter set and the fit-function.
from refnx.analysis import Parameter, Model
def line(x, params, *args, **kwds):
p_arr = np.array(params)
return p_arr[0] + x * p_arr[1]
# the model needs parameters
p = Parameter(1, "b", vary=True, bounds=(0, 10))
p |= Parameter(-2, "m", vary=True, bounds=(-5, 0.5))
model = Model(p, fitfunc=line)
We set lower and upper limits on each of the parameters. This means that the log-prior probability from those parameters is described by a uniform distribution. Only solutions which have finite probability (i.e. lie between the limits) will be considered by the fit/sampler.
# ln(1 / 10)
# a value lying outside the limits is not possible
print(p[0].logp(1), p[0].logp(-1))
-2.3025850929940455 -inf
It’s not required to give each parameter bounds unless the fit method requires it. The bounds do not have to be from a uniform distribution, any of the scipy.stats.rv_continuous distributions can be used:
import scipy.stats as stats
# a normal distribution of mean 5 and standard deviation 1.
p[0].bounds = stats.norm(5, 1)
Now we create an Objective from the model and the data. We use an extra parameter, lnsigma, to describe the underestimated error bars. Objectives use the model and data to calculate statistics about the curve fitting system.
from refnx.analysis import Objective
lnf = Parameter(0, "lnf", vary=True, bounds=(-10, 1))
objective = Objective(model, data, lnsigma=lnf)
print(objective.chisqr(), objective.logp(), objective.logl(), objective.logpost())
631.1788336329323 -6.405228458030841 -440.09147816937787 -446.4967066274087
Then a CurveFitter is created from the Objective. This is responsible for doing all the curvefitting/Bayesian sampling. Let’s do a quick fit using Differential Evolution.
from refnx.analysis import CurveFitter
fitter = CurveFitter(objective)
fitter.fit("differential_evolution");
61.76988450033622: : 20it [00:00, 487.36it/s]
In the final output of the sampling each varying parameter is given a set of statistics. Parameter.value is the median of the chain samples. Parameter.stderr is half the [15, 85] percentile, representing a standard deviation.
print(objective)
objective.plot();
________________________________________________________________________________
Objective - 4895160176
Dataset = <None>, 50 points
datapoints = 50
chi2 = 45.73170305997643
Weighted = True
Transform = None
________________________________________________________________________________
Parameters: None
<Parameter: 'b' , value=4.74604 +/- 0.261, bounds=[0.0, 10.0]>
<Parameter: 'm' , value=-1.09134 +/- 0.0598, bounds=[-5.0, 0.5]>
<Parameter: 'lnf' , value=-1.16894 +/- 0.202, bounds=[-10.0, 1.0]>
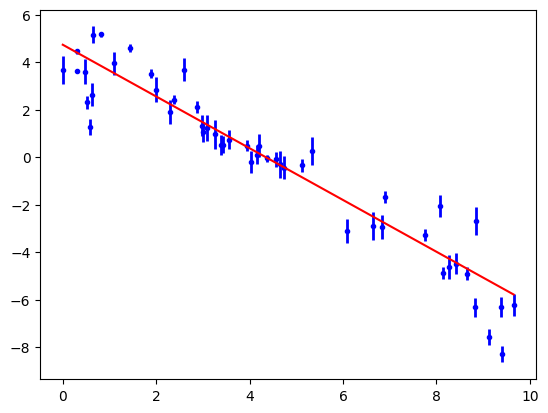
The trouble with a single fit that minimises \(\chi^2\) is that it doesn’t reveal the range of solutions that are consistent with the data. It also assumes that the parameter uncertainties will be normally distributed and uni-modal. To investigate the parameter probability distributions we need to use MCMC to sample the posterior probability distribution of the system.
Note: pool= specifies that no parallelisation is done during sampling. On platforms that use spawn for multiprocessing special precautions must be used when using pool > 1.
fitter.sample(1000, pool=1);
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:04<00:00, 239.86it/s]
Once the sampling is done we burn/discard some of the initial steps because the initial locations of the walkers won’t be around their ‘equilibrium’ position. We thin out the chain to reduce auto-correlation between successive steps.
from refnx.analysis import process_chain
process_chain(objective, fitter.chain, nburn=300, nthin=100, flatchain=True)
print(objective.parameters)
________________________________________________________________________________
Parameters: None
<Parameter: 'b' , value=4.73801 +/- 0.268, bounds=[0.0, 10.0]>
<Parameter: 'm' , value=-1.09034 +/- 0.0612, bounds=[-5.0, 0.5]>
<Parameter: 'lnf' , value=-1.14177 +/- 0.16 , bounds=[-10.0, 1.0]>
Now we can see the range of solutions that are consistent with the data:
objective.plot(samples=300);
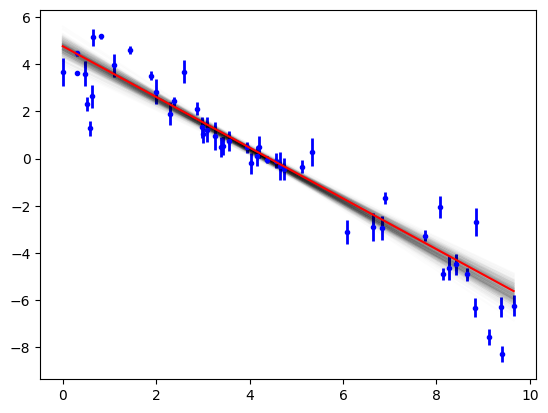
Fitting a neutron reflectometry dataset
We start off with all the relevant imports we’ll need.
from importlib import resources
import numpy as np
import matplotlib.pyplot as plt
import scipy
import refnx
from refnx.dataset import ReflectDataset, Data1D
from refnx.analysis import Transform, CurveFitter, Objective, Model, Parameter
from refnx.reflect import SLD, Slab, ReflectModel
It’s important to note down the versions of the software that you’re using, in order for the analysis to be reproducible.
print(
f"refnx: {refnx.version.version}\n"
f"scipy: {scipy.version.version}\n"
f"numpy: {np.version.version}"
)
refnx: 0.1.63.dev0+git20260318.81bb508
scipy: 1.17.1
numpy: 2.4.3
Loading/Creating a dataset
refnx reads 2, 3, or 4 column plain-text files using Data1D or ReflectDataset.
columns |
data |
|---|---|
2 |
\(x, y\) |
3 |
\(x, y, y_{err}\) |
4 |
\(x, y, y_{err}, x_{err}\) |
\(y_{err}\) being the standard deviation of the measured \(y\) data, \(x_{err}\) being the uncertainty in \(x\).
In a reflectometry context \(x\) is the momentum transfer \(Q\) (\(A^{-1}\)), \(y_{err}\) is the uncertainty in the reflectivity, and \(x_{err}\) is the full width at half maximum (FWHM) of the Gaussian approximation to the resolution function, \(dQ\).
The dataset we’re going to use as an example is distributed with every install. The following cell determines its location.
pth = resources.files(refnx.analysis)
DATASET_NAME = "c_PLP0011859_q.txt"
file_path = pth / f"tests/{DATASET_NAME}"
ReflectDataset uses a file path to load the data. However, you can also make a dataset directly from numerical arrays.
data = ReflectDataset(file_path)
Creating an interfacial Structure
Structure objects describe the interface of interest. They are made by assembling a series of Components (the simplest Component being a Slab. However, the first step is to create SLD objects that represent each of the materials:
si = SLD(2.07, name="Si")
sio2 = SLD(3.47, name="SiO2")
film = SLD(2.0, name="film")
d2o = SLD(6.36, name="d2o")
Slabs are created from these SLDs to represent each layer in the system.
# first number is thickness, second number is roughness
# a native oxide layer
sio2_layer = sio2(30, 3)
# you can also create a Slab using something like:
# sio2_layer = Slab(30, sio2, 3)
# the film of interest
film_layer = film(250, 3)
# layer for the solvent
d2o_layer = d2o(0, 3)
A Slab has the following parameters, which are all accessible as attributes:
Slab.thickSlab.sld.realSlab.sld.imagSlab.roughSlab.vfsolv
We need to specify which parameters are going to vary in a fit, and what the limits are on those parameters.
sio2_layer.thick.setp(bounds=(15, 50), vary=True)
sio2_layer.rough.setp(bounds=(1, 15), vary=True)
film_layer.thick.setp(bounds=(200, 300), vary=True)
film_layer.sld.real.setp(bounds=(0.1, 3), vary=True)
film_layer.rough.setp(bounds=(1, 15), vary=True)
d2o_layer.rough.setp(vary=True, bounds=(1, 15))
Now we assemble the Structure from the Components.
structure = si | sio2_layer | film_layer | d2o_layer
print(sio2_layer.parameters)
________________________________________________________________________________
Parameters: 'SiO2'
<Parameter:'SiO2 - thick' , value=30 , bounds=[15.0, 50.0]>
________________________________________________________________________________
Parameters: 'SiO2'
<Parameter: 'SiO2 - sld' , value=3.47 (fixed) , bounds=[-inf, inf]>
<Parameter: 'SiO2 - isld' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter:'SiO2 - rough' , value=3 , bounds=[1.0, 15.0]>
<Parameter:'SiO2 - volfrac solvent', value=0 (fixed) , bounds=[0.0, 1.0]>
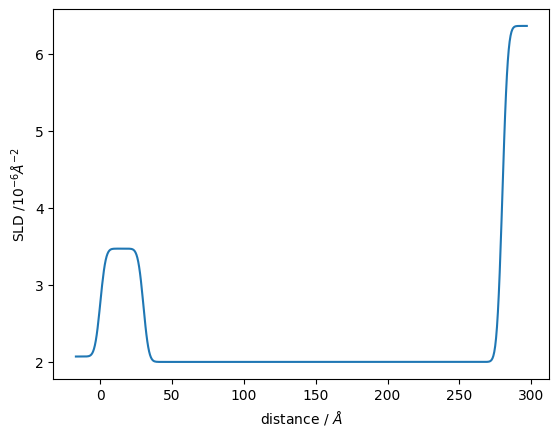
Structure has a sld_profile method to return the SLD profile. Let’s also plot that.
plt.plot(*structure.sld_profile())
plt.ylabel("SLD /$10^{-6} \\AA^{-2}$")
plt.xlabel("distance / $\\AA$");
ReflectModel calculates the generative model.
A ReflectModel is made from the Structure and is responsible for calculating the reflectivity of the system. ReflectModel performs resolution smearing, applies scaling factor and adds a Q-independent constant background. It can use constant dq/q, point-by-point, and full resolution kernel smearing. The resolution parameter, dq, can be fitted, but this will only be valid if your dataset didn’t supply the instrument resolution.
model = ReflectModel(structure, bkg=3e-6, dq=5.0)
model.scale.setp(bounds=(0.6, 1.2), vary=True)
model.bkg.setp(bounds=(1e-9, 9e-6), vary=True)
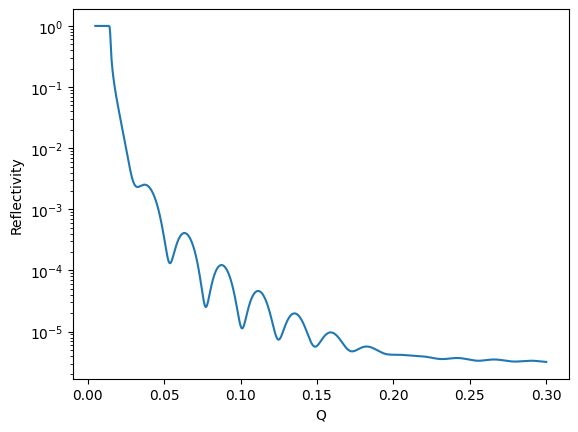
Let’s quickly have a look at the model generated by the structure:
q = np.linspace(0.005, 0.3, 1001)
plt.plot(q, model(q))
plt.xlabel("Q")
plt.ylabel("Reflectivity")
plt.yscale("log")
Objective combines the model and data, calculating statistics
An Objective is made from a model and dataset. Here we use a Transform to fit as logY vs X.
objective = Objective(model, data, transform=Transform("logY"))
The Objective can calculate statistics for the fitting system. Note how the log-probability is the sum of the log-prior and log-likelihood.
print(objective.chisqr(), objective.logp(), objective.logl(), objective.logpost())
34376.69092305149 -5.013178251637257 -16157.428065740665 -16162.441243992302
CurveFitter does the fitting/sampling
The final setup step is to create a CurveFitter from the Objective. These objects do the fitting/sampling. Let’s do an initial fit with differential evolution.
fitter = CurveFitter(objective)
fitter.fit("differential_evolution");
-568.9488406210648: : 46it [00:02, 17.25it/s]
An Objective has a plot method, which is a quick visualisation. You need matplotlib installed to create a graph. You can see that the fit looks good.
objective.plot()
plt.legend()
plt.xlabel("Q")
plt.ylabel("logR")
plt.legend();
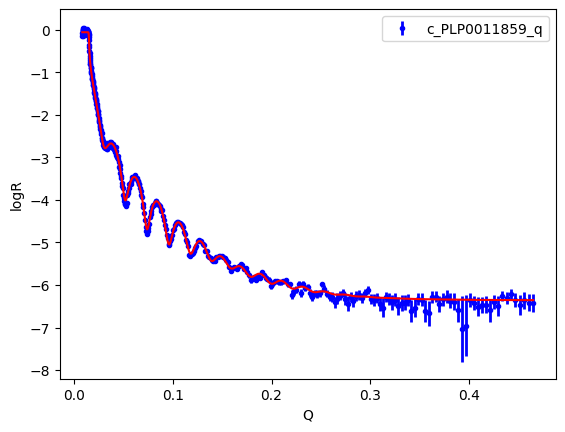
Let’s see the results of the fit. For the case of DifferentialEvolution uncertainties are estimated by estimating the Hessian/Covariance matrix.
print(objective)
________________________________________________________________________________
Objective - 4922706832
Dataset = c_PLP0011859_q
datapoints = 408
chi2 = 921.7684635401719
Weighted = True
Transform = Transform('logY')
________________________________________________________________________________
Parameters: ''
________________________________________________________________________________
Parameters: 'instrument parameters'
<Parameter: 'scale' , value=0.878379 +/- 0.00305, bounds=[0.6, 1.2]>
<Parameter: 'bkg' , value=4.38859e-07 +/- 2.12e-08, bounds=[1e-09, 9e-06]>
<Parameter:'dq - resolution', value=5 (fixed) , bounds=[-inf, inf]>
<Parameter: 'q_offset' , value=0 (fixed) , bounds=[-inf, inf]>
________________________________________________________________________________
Parameters: 'Structure - '
________________________________________________________________________________
Parameters: 'Si'
<Parameter: 'Si - thick' , value=0 (fixed) , bounds=[-inf, inf]>
________________________________________________________________________________
Parameters: 'Si'
<Parameter: 'Si - sld' , value=2.07 (fixed) , bounds=[-inf, inf]>
<Parameter: 'Si - isld' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter: 'Si - rough' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter:'Si - volfrac solvent', value=0 (fixed) , bounds=[0.0, 1.0]>
________________________________________________________________________________
Parameters: 'SiO2'
<Parameter:'SiO2 - thick' , value=38.957 +/- 0.376, bounds=[15.0, 50.0]>
________________________________________________________________________________
Parameters: 'SiO2'
<Parameter: 'SiO2 - sld' , value=3.47 (fixed) , bounds=[-inf, inf]>
<Parameter: 'SiO2 - isld' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter:'SiO2 - rough' , value=5.82041 +/- 0.284, bounds=[1.0, 15.0]>
<Parameter:'SiO2 - volfrac solvent', value=0 (fixed) , bounds=[0.0, 1.0]>
________________________________________________________________________________
Parameters: 'film'
<Parameter:'film - thick' , value=258.86 +/- 0.251, bounds=[200.0, 300.0]>
________________________________________________________________________________
Parameters: 'film'
<Parameter: 'film - sld' , value=2.40563 +/- 0.0129, bounds=[0.1, 3.0]>
<Parameter: 'film - isld' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter:'film - rough' , value=8.97418 +/- 0.37 , bounds=[1.0, 15.0]>
<Parameter:'film - volfrac solvent', value=0 (fixed) , bounds=[0.0, 1.0]>
________________________________________________________________________________
Parameters: 'd2o'
<Parameter: 'd2o - thick' , value=0 (fixed) , bounds=[-inf, inf]>
________________________________________________________________________________
Parameters: 'd2o'
<Parameter: 'd2o - sld' , value=6.36 (fixed) , bounds=[-inf, inf]>
<Parameter: 'd2o - isld' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter: 'd2o - rough' , value=3.67537 +/- 0.113, bounds=[1.0, 15.0]>
<Parameter:'d2o - volfrac solvent', value=0 (fixed) , bounds=[0.0, 1.0]>
Now lets do a MCMC sampling of the curvefitting system. First we do 400 samples which we then discard (burn). These samples are discarded because the initial chain might not be representative of an equilibrated system (i.e. distributed around the mean with the correct covariance).
fitter.sample(400, pool=-1)
fitter.reset()
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 400/400 [00:23<00:00, 16.86it/s]
We then follow up with a production run, only saving 1 in 100 samples. This is to remove autocorrelation. We save 15 steps, giving a total of 15 * 200 samples (200 walkers is the default).
res = fitter.sample(15, nthin=100, pool=-1)
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1500/1500 [01:32<00:00, 16.20it/s]
In the final output of the sampling each varying parameter is given a set of statistics. Parameter.value is the median of the chain samples. Parameter.stderr is half the [15, 85] percentile, representing a standard deviation.
print(objective)
________________________________________________________________________________
Objective - 4922706832
Dataset = c_PLP0011859_q
datapoints = 408
chi2 = 919.5974066956189
Weighted = True
Transform = Transform('logY')
________________________________________________________________________________
Parameters: ''
________________________________________________________________________________
Parameters: 'instrument parameters'
<Parameter: 'scale' , value=0.87932 +/- 0.00311, bounds=[0.6, 1.2]>
<Parameter: 'bkg' , value=4.59684e-07 +/- 2.27e-08, bounds=[1e-09, 9e-06]>
<Parameter:'dq - resolution', value=5 (fixed) , bounds=[-inf, inf]>
<Parameter: 'q_offset' , value=0 (fixed) , bounds=[-inf, inf]>
________________________________________________________________________________
Parameters: 'Structure - '
________________________________________________________________________________
Parameters: 'Si'
<Parameter: 'Si - thick' , value=0 (fixed) , bounds=[-inf, inf]>
________________________________________________________________________________
Parameters: 'Si'
<Parameter: 'Si - sld' , value=2.07 (fixed) , bounds=[-inf, inf]>
<Parameter: 'Si - isld' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter: 'Si - rough' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter:'Si - volfrac solvent', value=0 (fixed) , bounds=[0.0, 1.0]>
________________________________________________________________________________
Parameters: 'SiO2'
<Parameter:'SiO2 - thick' , value=38.6415 +/- 0.367, bounds=[15.0, 50.0]>
________________________________________________________________________________
Parameters: 'SiO2'
<Parameter: 'SiO2 - sld' , value=3.47 (fixed) , bounds=[-inf, inf]>
<Parameter: 'SiO2 - isld' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter:'SiO2 - rough' , value=5.82361 +/- 0.299, bounds=[1.0, 15.0]>
<Parameter:'SiO2 - volfrac solvent', value=0 (fixed) , bounds=[0.0, 1.0]>
________________________________________________________________________________
Parameters: 'film'
<Parameter:'film - thick' , value=259.039 +/- 0.247, bounds=[200.0, 300.0]>
________________________________________________________________________________
Parameters: 'film'
<Parameter: 'film - sld' , value=2.40219 +/- 0.0129, bounds=[0.1, 3.0]>
<Parameter: 'film - isld' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter:'film - rough' , value=8.82437 +/- 0.359, bounds=[1.0, 15.0]>
<Parameter:'film - volfrac solvent', value=0 (fixed) , bounds=[0.0, 1.0]>
________________________________________________________________________________
Parameters: 'd2o'
<Parameter: 'd2o - thick' , value=0 (fixed) , bounds=[-inf, inf]>
________________________________________________________________________________
Parameters: 'd2o'
<Parameter: 'd2o - sld' , value=6.36 (fixed) , bounds=[-inf, inf]>
<Parameter: 'd2o - isld' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter: 'd2o - rough' , value=3.79385 +/- 0.114, bounds=[1.0, 15.0]>
<Parameter:'d2o - volfrac solvent', value=0 (fixed) , bounds=[0.0, 1.0]>
A corner plot shows the covariance between parameters. You need to install the matplotlib and corner packages to create these graphs.
objective.corner();

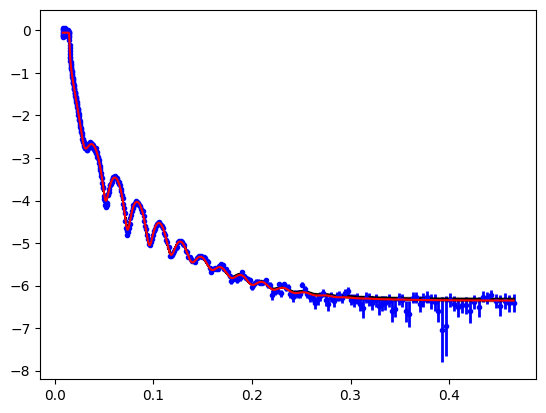
Once we’ve done the sampling we can look at the variation in the model at describing the data. In this example there isn’t much spread.
objective.plot(samples=300);
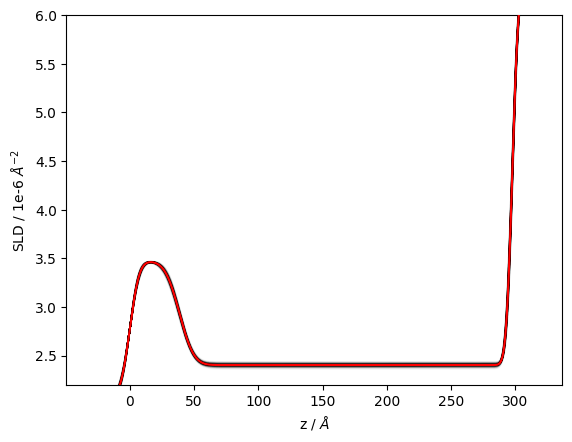
In a similar manner we can look at the spread in SLD profiles consistent with the data.
structure.plot(samples=300)
plt.ylim(2.2, 6);
Fitting the BornAgain example
BornAgain is another program for fitting reflectometry and GISAS data. The following cells repeat an analysis originally found in their repository. The simulated thickness of the Titanium layer is 30 Angstrom, but we’ll start the fit with a value of 50.
# necessary imports
import numpy as np
from refnx.util import q
from refnx.analysis import Objective, CurveFitter, Transform
from refnx.dataset import Data1D
from refnx.reflect import SLD, Stack, ReflectModel
# first grab the data. It can be found in the BornAgain repository,
# but it's been archived in the refnx-testdata repository.
# The data was originally created in genx.
import requests as req
import io
import gzip
url = (
"https://github.com/refnx/refnx-testdata/raw/refs/heads/master/data/reflect/genx_alternating_layers.dat.gz"
)
f = gzip.open(io.BytesIO(req.get(url).content))
dataset = np.loadtxt(f, usecols=(0, 1), skiprows=3).T
# data is saved as two_theta, convert to Q.
dataset[0] = q(dataset[0] / 2, 1.54)
# make a dataset
data = Data1D(data=dataset)
# make the structure
air = SLD(0)
si = SLD(2.0704) # silicon substrate
ni = SLD(9.4245) # nickel
ti = SLD(-1.9493) # titanium
# make the layers
ti_layer = ti(50)
ni_layer = ni(70)
# Make a multilayer by using a Stack Component
stack = Stack()
stack |= ti_layer
stack |= ni_layer
stack.repeats.value = 10
# The `|=` syntax is a way of appending Components to the Stack. You can also use that
# syntax to append Components to a Structure.
# An alternative way of creating the Stack would be:
# stack = Stack(components=(ti_layer, ni_layer), repeats=10)
structure = air | stack | si(0, 0)
# put the Structure in a Model
model = ReflectModel(structure, bkg=0, dq=0)
# we're only going to fit the Titanium thickness
ti_layer.thick.setp(vary=True, bounds=(10, 60))
# now do the fit
objective = Objective(model, data, transform=Transform("logY"))
fitter = CurveFitter(objective)
# now fit and plot
fitter.fit("differential_evolution")
fig, ax = objective.plot()
1.0115324738577631e-07: : 27it [00:00, 75.00it/s]
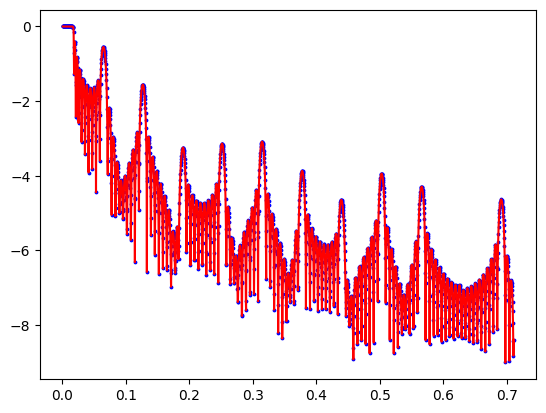
print(objective.chisqr())
print(ti_layer)
2.0230618137099573e-07
________________________________________________________________________________
Parameters: ''
<Parameter: ' - thick' , value=30 +/- 4.43e-08, bounds=[10.0, 60.0]>
________________________________________________________________________________
Parameters: ''
<Parameter: ' - sld' , value=-1.9493 (fixed) , bounds=[-inf, inf]>
<Parameter: ' - isld' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter: ' - rough' , value=0 (fixed) , bounds=[-inf, inf]>
<Parameter:' - volfrac solvent', value=0 (fixed) , bounds=[0.0, 1.0]>